sktime provides an open-source framework for machine learning with time series. In this GSoC program, I focused on time series annotation (i.e. anomaly detection, segmentation, clustering).
Major Projects

HIDALGO: Heterogeneous Intrinsic Dimensionality ALGOrithm
A fundamental paradigm in machine learning is that a small number of variables is often sufficient to describe high-dimensional data, where Intrinsic dimensionality (ID) is the minimum number of variables required. In most approaches for dimensionality reduction and manifold learning, the ID is assumed to be constant in the dataset. However, this assumption is often violated in the case of real-world data. Heterogeneous ID allows for data to be represented by a mixture model on the support on the union of K manifolds with varying dimensions. Points are then assigned to manifold k with corresponding dimensionality. Hidalgo extends this concept to a Bayesian framework which allows the identification (by Gibbs sampling) of regions in the data landscape where the ID can be considered constant. As such, Hidalgo offers robust method for unsupervised segmentation of high-dimensional data.
References
See the paper and reference code, originally implemented in MATLAB/C/C++/python. Refactor (and re-write) was necessary due to the source code not being packageable (while also having dependencies).
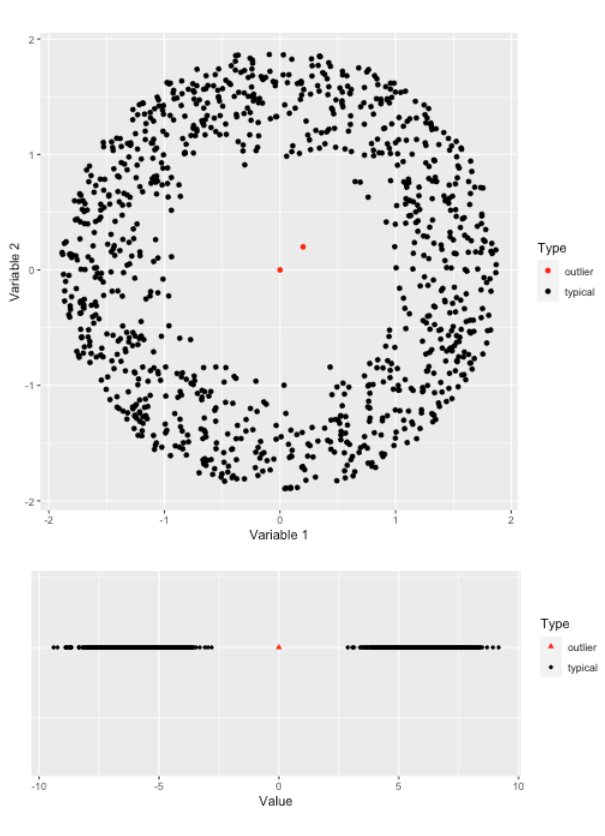
STRAY: Search TRace AnomalY outlier estimator
STRAY is an extension of HDoutliers, a powerful algorithm for the detection of anomalous observations in a dataset which has (among other advantages) the ability to detect clusters of outliers in multi-dimensional data without requiring a model of the typical behavior of the system. However, it suffers from some limitations that affect its accuracy. STRAY is an extension of HDoutliers that uses extreme value theory for the anomalous threshold calculation, to deal with data streams that exhibit non-stationary behavior.
References
See the paper and reference code, originally implemented in R.
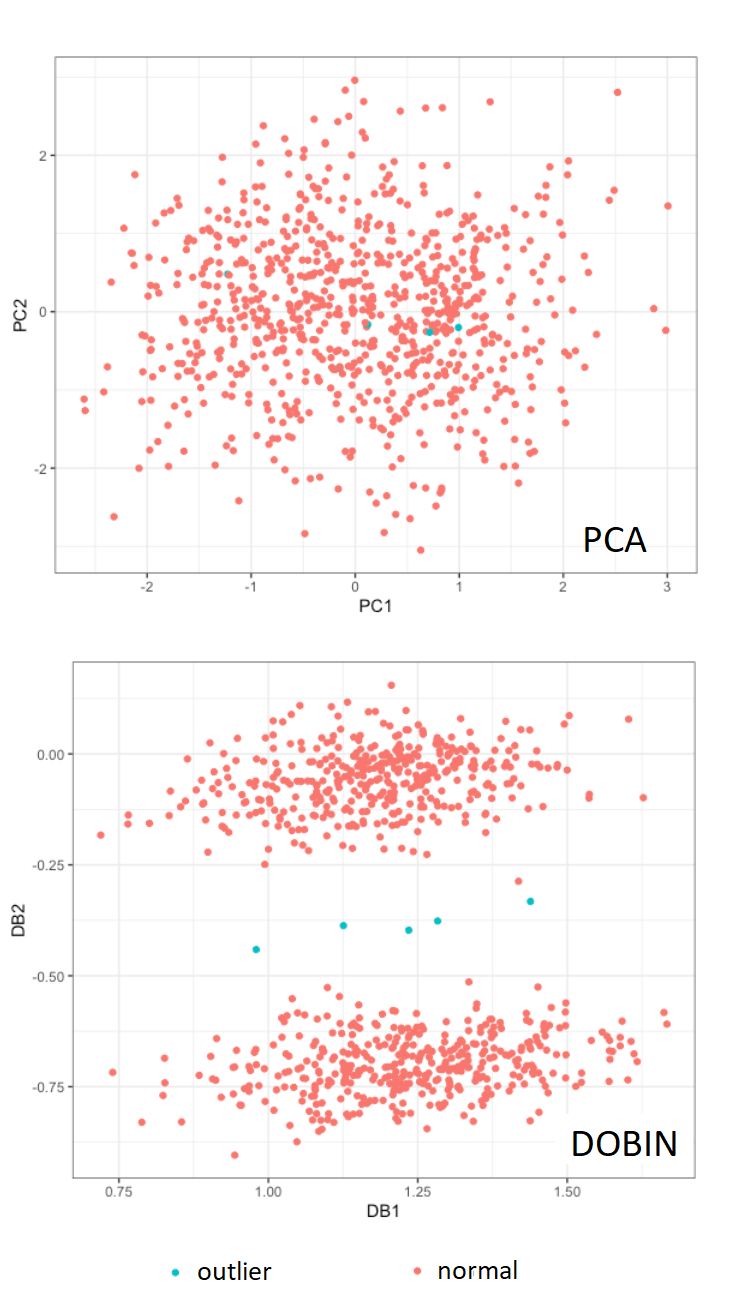
DOBIN: Distance based Outlier BasIs using Neighbors
Outlier detection is used in diverse applications such as the identification of extreme weather events, stock market crashes and fraudulent transactions. A common challenge in many domains is that a data point may be an outlier in the original high dimensional space, but not an outlier in the low dimensional subspace created by a dimension reduction method. It is common to use Principal Component Analysis (PCA) for dimension reduction when detecting outliers, however PCA finds a set of basis vectors that explains the variance of the data, such that the highest variance is in the direction of the first vector, and so on. As such, outliers can be lost in this pre-processing step. DOBIN constructs a set of basis vectors specifically tailored for unsupervised outlier detection to be used as a dimension reduction tool for outlier detection tasks.
References
See the paper and reference code, originally implemented in R.
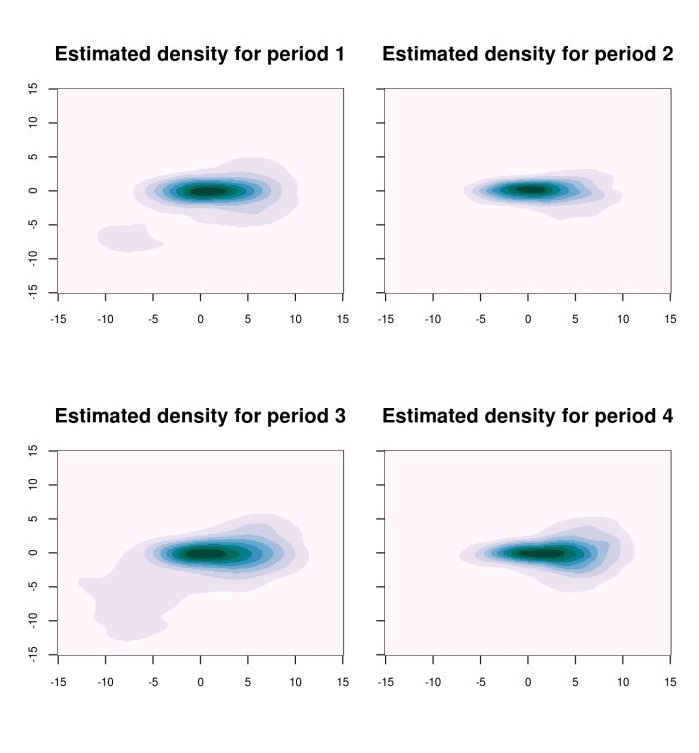
EAGGLO: Hierarchical agglomerative estimation
E-Agglo is a non-parametric clustering approach for multivariate timeseries, where neighbouring segments are sequentially merged to maximize a goodness-of-fit statistic. Unlike most general purpose agglomerative clustering algorithms, this procedure preserves the time ordering of the observations. Estimation is performed in a manner that simultaneously identifies both the number and locations of change points.
References
See the paper and reference code, originally implemented in R/C++.